객체 지향 프로그래밍#
객체 지향 프로그래밍(object-oriented programming)은 좀 더 나은 프로그램을 만들기 위한 프로그래밍 패러다임으로 로직을 데이터(상태, 속성)와 행동(행위, 함수, 방법)으로 이루어진 객체로 만드는 것이다. 이 객체들을 마치 레고 블럭처럼 조립해서 하나의 프로그램을 만드는 것이 객체지향 프로그래밍이라고 할 수 있다. 다시 말해서 객체지향 프로그래밍은 객체를 만드는 것이다.
객체 지향 프로그래밍을 학습하는데 장애 중의 하나는 번역이다. Object를 번역한 객체는 현실에서는 거의 쓰지 않는 말이고, 머랄까 철학적인 느낌을 자아낸다. 그래서 객체 지향 프로그래밍을 처음 접하는 입문자들은 객체 지향 프로그래밍을 철학적인 탐구의 대상으로 파악하는 경향을 보이는데, 필자의 생각에 이것은 공부를 어렵게 할 뿐 도움이 되지 않는다. 쉽게 생각하자. 객체는 변수와 메소드를 그룹핑한 것이다. - 생활코딩
설계의 이해#
설계하면 대개 건축 분야가 먼저 떠오를 것이다. 건축에서 고객의 요구사항을 반영해 설계 도면을 만들고 현장에서 이 도면을 토대로 건물을 짓는다. 건축에서 설계는 어떤 단계를 거쳐 이루어질까? 건축주는 짓고 싶은 집의 모양을 구상하고 집의 형태, 외관, 공간이나 방의 개수 및 위치 등을 건축사에게 제시할 것이다. 설계사는 건축주의 요구사항과 경험으로 터득한 제약 사항 등을 토대로 그린 도면을 제시하며 자세히 설명할 것이다. 건축주와 설계사가 의견 교환을 통해 도면을 확정하면 시공에 들어간다. 이 과정에서 최종 산출물로 설계 도면이 만들어진다. 도면은 일반인들도 이해할 수 있는 도면부터 공사 현장에서 참조하는 전기 배선도, 상하수도 배관도에 이르기까지 필요에 따라 여러 형태로 제작된다. 다시 말해, 모든 고수준의 결정사항을 지탱하는 모든 세부사항을 확인할 수 있다. 이러한 저수준의 세부사항과 고수준의 결정사항은 집의 전체 설계의 구성요소가 된다.
소프트웨어 설계도 마찬가지다. 사용자의 요구사항에 다라 요구분석명세서가 만들어지면 이를 참조해 개발팀에서 설계서(건축의 설게 도면에 해당)를 작성한 뒤 이를 기반으로 구현 작업을 진행한다. 요구분석명세서를 기반으로 만든 설계서는 건축의 다양한 도면처럼 사용자 인터페이스 설계, 아키텍처 설계, 클래스 설계 등 여러 형태로 구체화된다. 저수준의 세부사항과 고수준의 구조는 모두 소프트웨어 전체 설계의 구성요소이며 이 둘은 단절 없이 이어진 직물과 같다. 이를 통해 대상 시스템의 구조를 정의한다. 개별로는 존재할 수 없고 실제 이 둘을 구분 짓는 경계는 뚜렷하지 않다. 고수준에서 저수준으로 향하는 의사결정의 연속성만 있을 뿐이다. 다음은 요구분석과 설계의 차이를 나타낸 표이다.
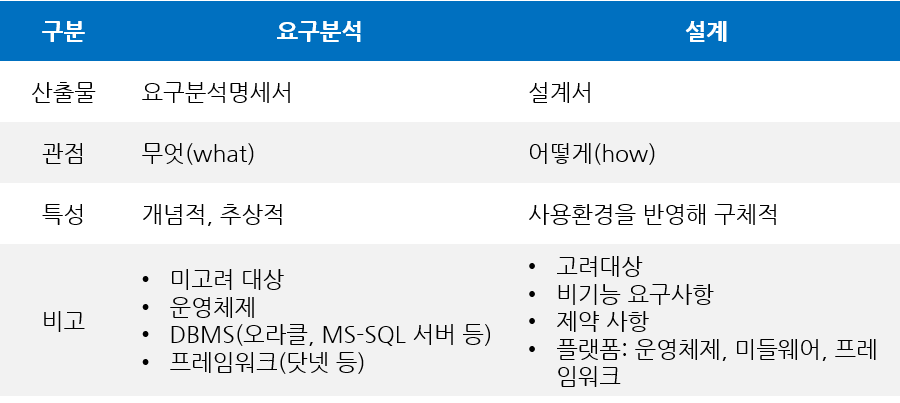
설계는 요구분석명세서를 기반으로 어떻게 구축할 것인가를 결정한다. 따라서 여러 방법 중 다양한 제약 조건을 만족하는 최적의 설계서를 만드는 것이 중요하며 설계를 평가할 수 있는 기준도 정량적으로 명시해야 한다. 좋은 설계가 되기 위한 조건은 다음과 같다.
설계서는 요구분석명세서의 내용을 모두 포함해야 한다.
유지보수가 용이하도록 추적이 가능해야 한다.
변화에 쉽게 적응할 수 있어야 한다.
시스템 변경으로 인한 영향이 최소화되도록 국지적이어야 한다.
설계서는 읽기 쉽고 이해하기 쉽게 작성해야 한다.
위의 조건을 만족하는 좋은 설계가 되려면 결국 모듈이 독립적이어야 하고 모듈 내 요소 간의 응집도는 강하게 모듈 간 결합도는 느슨하게 설계되어야 한다.
설계의 원리#
세 가지 패러다임인 구조적 프로그래밍, 객체 지향 프로그래밍, 함수형 프로그래밍이 있다. 구조적 프로그래밍은 1968년 에츠허르 비버 데이크스트라(Edsger Wybe Dijkstra)가 제안했다. 데이크스트라는 무분별한 점프(goto)는 프로그램 구조에 해롭우며 이러한 점프들을 if/then/else와 do/while/until과 같은 구조로 대체하였다. 구조적 프로그래밍은 제어흐름의 집적적인 전화에 대해 규칙을 부과한다. 객체 지향 프로그래밍은 구조적 프로그래밍보다 2년 앞서 1966년 올레 요한 달(Ole Johan Dahl)과 크리스텐 니가드(Kristen Nygaard)에 의해 등장했다. 알골(ALGOL) 언어의 함수 호출 스택 프레임을 힙(heap)으로 옮기면, 함수 호출이 반환된 이후에도 함수에서 선언된 지역 변수가 오랫동안 유지되는 것을 발견하고 이러한 함수가 클래스의 생성자가 되었고, 지역 변수는 인스턴스 변수, 중첩 함수는 메서드가 되었다. 함수 포인터를 특정 규칙에 따라 사용하는 과정을 통해 필연적으로 다형성이 등장하게 되었다. 객체 지향 프로그래밍은 제어흐름의 간접적인 전환에 대해 규칙을 부과하는 것이다. 마지막으로 함수형 프로그래밍은 최근에 도입되기 시작했지만, 세 패러다임 중 가장 먼저 만들어졌다. 알론조 처치(Alonzo Church)는 앨런 튜링도 똑같이 흥미를 느꼈던 어떤 수학적 문제를 해결하는 과정에서 람다(lambda) 계산법을 발명했는데, 함수형 프로그래밍은 이러한 연구 결과에 직접적인 영향을 받아 만들어졌다. 1958년 존 메카시(John McCarthy)가 만든 LISP 언어의 근간이 되는 개념이 람다 계산법이다. 람다 계산법은 불변성(immutability)으로 심볼(symbol) 값이 변경되지 않는다는 개념이다. 함수형 언어에는 할당문이 전혀 없다는 뜻이기도 하다. 함수형 프로그래밍은 할당문에 대해 규칙을 부과한다.
좋은 아키텍처를 만드는 일은 객체 지향 설계 원칙을 이해하고 응용하는 데서 출발한다. 그럼 객체 지향이란 무엇인가? 객체 지향은 데이터와 함수의 조합이라고 간단하게 답할 수 있다. 또는 ‘실제 세계를 모델링하는 새로운 방법’이라고 답할 수도 있다. 객체 지향의 본질을 설명하기 위해서 세 가지 요소인 캡슐화, 상속, 다형성이 있다. 이들의 적절하게 조합한 것이나 또는 객체 지향 언어는 최소한 세 가지 요소를 반드시 지원해야 한다고 말한다.
분할과 정복#
큰 조직을 운영하려면 여러 개의 세부 조직으로 나누고 또 그안에서 더 작은 조직으로 나누어 관리하는 것이 효율적이다. 기업의 경우에도 몇 개의 사업부로 나눈 뒤 사업부를 부서로 부서를 과로 나누어 운영한다. 소프트웨어 개발도 이와 유사한 원리를 적용한다. 규모가 큰 소프트웨어 하나를 개발할 때 여러 개의 서브시스템으로 나누고 서브시스템은 다시 규모가 더 작은 서브시스템으로 나눈 후 하나씩 개발해 나간다. 예를 들어 대학의 종합정보시스템도 그림처럼 세분화하고 있다.
분할은 세분화해 나누는 작업으로 어느 정도 수준까지 분할했다면 말단에 있는 것부터 하나씩 개발하는데 이것이 정복이다. 분할과 정복(divide and conquer)의 원리는 프로젝트를 수행할 때 먼저 작은 단위로 분할한 뒤 말단에 있는 작은 시스템부터 개발하면서 하나씩 위로 올라가며 완성하는 것이다. 이 원리는 하나의 일을 수행할 때 작은 단위로 나누고 각각의 작은 단위를 하나씩 처리해 전체 일을 끝낸다는 의미다. 소프트웨어 개발에 분할과 정보의 원리를 적용하려면 우선 모듈로 분할하는 작업을 해야 한다. 프로젝트의 특성에 따라 소프트웨어 모듈로 다음과 같이 분할할 수 있다.
분산 시스템은 클라이언트와 서버로 분할한다.
시스템은 여러 서브시스템으로 분할한다.
서브시스템은 하나 이상의 패키지로 분할한다.
패키지는 유스케이스나 여러 클래스로 분할한다
소프트웨어 개발에서 규모가 큰 문제를 작은 규모의 모듈로 분할해 문제를 해결하는 것은 매우 유용하다. 그런데 여러 개의 모듈로 분할하면 모듈끼리 통신 횟수가 많아지면서 모듈로 분할하는 장점보다 복잡도가 오히려 증가할 수 있다. 설계자는 어느 수준까지 목표를 분할할지 결정할 때 복잡도 증가로 인한 부작용과 모듈 분할로 얻는 이득을 함께 고려해야 한다.
추상화#
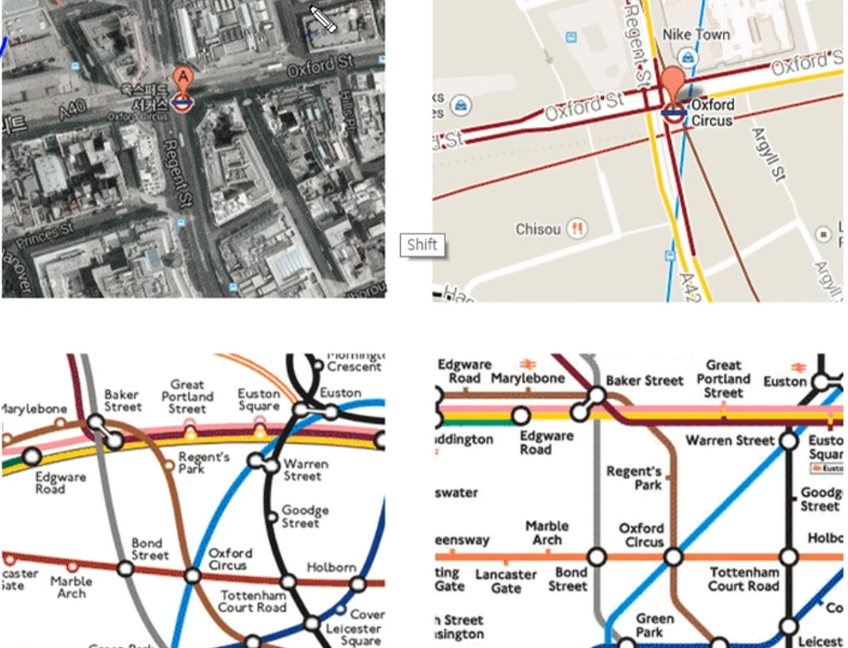
추상화(abstraction)는 좋은 객체를 만드는 방법이다. 이것을 다른 말로는 설계를 잘하는 법이라고 할 수 있다. 좋은 설계는 현실을 잘 반영해야 한다. 현실은 복잡하다. 하지만 그 복잡함 전체가 필요한 것은 아니다. 아래의 그림을 보자. 위의 그림은 런던의 지도다. 여러분이 지하철을 이용한다면 어떤 지도를 선호할까? 오른쪽 하단의 지도를 선호할 것이다. 왼쪽 상단의 지도는 현실의 복잡함을 나타낸다. 오른쪽 하단의 지도는 지하철 탑승자의 관심사만을 반영하고 있다. 역 간의 거리나 실제 위치와 같은 요소들은 모두 배제하고 있다. 복잡함 속에서 필요한 관점만을 추출하는 행위를 추상화라고 한다.
지하철 노선도가 디자인의 추상화라고 한다면 프로그램을 만든다는 것은 소프트웨어의 추상화라고 할 수 있다. 객체 지향 프로그래밍은 좀 더 현실을 잘 반영하기 위한 노력의 산물이다. 이것은 단순히 객체 지향의 문법을 이용해서 객체를 만든다고 달성되는 것이 아니다. 고도의 추상화 능력이 필요하다. 좋은 설계는 문법을 배우는 것보다 훨씬 어려운 일이다. 심지어 이것은 지식을 넘어서 지혜의 영역이다. 좋은 설계를 위한 조언들은 많지만 이러한 조언들은 조언자의 입을 떠나는 순간 생명력을 잃어버린다. 지식은 전수되지만 지혜는 전수되지 않기 때문이다. 스스로 경험하고 깨우쳐서 자기화시켜야 한다. 필자도 그 긴 여정을 따라가고 있는 견습생에 불과하다.
객체 지향의 설계 원칙이나 객체 지향의 철학적인 의미는 대단히 중요하다. 하지만 이러한 것들을 지금 언급한다면 여러분은 미궁 속에 빠지게 될 것이다. 그래서 필자가 제안하는 것은 일단은 지식부터 익히자는 것이다. 언어가 지원하는 객체지향 문법을 배우고, 이것들이 어떻게 동작하는지를 충분히 이해한 다음에 비로소 설계 원칙도 이야기할 수 있고, 객체와 사물의 비유도 시도해 볼 수 있을 것이다. 여기서는 몇 가지 객체지향이 추구하는 지향점을 가볍게 이야기하고 다음 토픽부터 구체적인 문법을 알아볼 것이다.

추상화는 소프트웨어 설계에서 매우 중요한 개념이다. 설계의 수준을 평가할 때 얼마나 추상화가 잘 되었느냐에 따라 좋은 설계와 그렇지 않은 설계로 나눌 수 있으며 추상화가 잘된 설계일수록 유지보수를 쉽게 할 수 있다. 추상화의 개념은 설계 패턴에서도 유용하게 사용된다. 추상화란 자신에게 필요한 특징만 표현한 것이라 할 수 있다. 산을 타나낼 때 등산가는 등산로 그림이 필요하고 지형을 연구하는 사람은 등고선 그림이 필요할 것이다. 건설 현장 안내문에서 볼 수 있는 조감도는 완성될 건물의 전체 모습을 알 수 있지만 전기 배선 공사 담당자에게는 전기 배선도, 배관 설치 담당자에게는 상하수도 배관도가 필요할 것이다. 이처럼 각자 필요한 특징만 찾아내어 나타낸 도면을 추상화의 개념으로 볼 수 있다.
추상화는 주어진 문제(건물 도면)에서 현재의 관심사에 초점을 맞추기 위해 특정한 목적과 관련된 필수 정보만 추출해 강조하고(전기 배선도, 상하수도 배관도 등) 관련 없는 세부 사항은 생략해 본질적인 문제에 집중할 수 있도록 하는 작업이다. 추상화는 복잡한 세부 사항을 모두 다루는 것이 불가능하고 필요도 없으므로 복잡한 현상을 간단히 이해할 수 있게 도와주는 강력한 도구로 사용된다.
문제를 해결하기 어려운 대표적인 이유는 규모가 크고 복잡하기 때문이다. 이러한 문제는 설계에서도 발생하는데 추상화 개념을 사용하면 문제의 핵심을 쉽게 파악할 수 있고 문제의 본질을 이해하는데도 도움이 된다. 객체 지향 설계에서 추상화의 의미는 약간 다르게 사용된다… 그림에서 도형의 계층을 보면 직선과 곡선의 공통점을 뽑아 개곡선이라고 이름을 붙이고 원, 사각형, 삼각형의 공통점을 뽑아 폐곡선이라고 이름을 붙였다. 타원 정원의 공통점을 뽑아 원이라고 이름을 붙이고 사각형과 삼각형도 같은 방식으로 이름을 붙였다. 객체지향 설계에서 추상화는 유사한 특성을 가진 것 끼리 그룹화한 뒤 공통점을 뽑아 이름을 붙이는 것을 말한다.
추상화 방법에는 프로그램을 알고리즘 형태로 작성하는 과정 추상화(procedure abstraction) 데이터를 모아 데이터 구조 형태로 표현하는 데이터 추상화, 여러 줄의 내용을 간략하게 줄여 표현하는 제어 추상화가 있다.
과정 추상화#
주어진 문제에 대해 프로그래밍하기 전에 상세 부분은 생략하고 전체 흐름만 파악할 수 있는 알고리즘 형태로 작성하는 것을 과정 추상화라고 한다. 그림은 학생들의 학점을 계산하는 전체 흐름을 나타내는 알고리즘으로 과정 추상화의 예이다.
학생 데이터 파일을 읽어 온다.
학생 한 명의 과목별 점수의 합계 및 평균을 구한다.
합계 점수를 내림차순으로 정렬한다.
상위 10%는 A+ 학점을 준다.
상위 30%까지는 B+ 학점을 준다.
학생 이름과 평균 점수, 학점을 출력한다.
위 알고리즘에서 ‘학점을 구하는 과목의 이름은 구체적으로 언급하지 않고 합계 및 평균을 구한다.’ 라고만 표현했고 과목의 점수 합계를 정렬할 때도 구체적인 방법(버블 정렬, 퀵 정렬, 선택 정렬 등)은 언급하지 않고 정렬한다라고만 표현했다.
데이터 추상화#
데이터 추상화는 데이터와 데이터 구조를 감추는 것으로 대표적인 예가 C++ 언어의 클래스이다. 클래스는 데이터와 함수를 하나로 묶어 캡슐화한 구조로 사용자는 클래스에서 제공하는 기능(method)만 알고 사용한다. 이는 마치 오디오나 세탁기 등과 같은 전자 제품의 자세한 작동 원리를 몰라도 사용법만 알면 사용할 수 있는 것과 유사하다.
그림은 자료구조에서 다루는 스택의 클래스를 간략히 나타낸 것이다. 스택은 데이터가 1개씩 증가할 때마다 스택 안에 쌓이고 1개씩 감소할 때마다 스택 안에 있는 요소를 1개씩 제거하는 자료구조이다. 세탁기에 어떤 기능이 있고 이 기능을 사용하려면 어떤 버튼을 누르면 되는지 알면 되는 것처럼 스택을 이용하는 입장에서는 스택이 제공하는 기능만 알면 되는데 이것이 바로 push와 pop이다. 따라서 사용자는 각 어떤 기능을 하는지만 알면 된다. 이처럼 데이터 추상화는 데이터와 메서드를 클래스 형태로 캡슐화해 숨겨 놓고 사용자에게는 꼭 필요한 기능만 사용할 수 있게 개방한 구조이다.
제어 추상화#
제어 추상화는 프로그래밍 언어에서 쓰는 제어 구조를 추상화하는 것이다. 예를 들어 그림의 C언어 같은 고급 언어로 표현한 것이고 (b)는 이를 어셈블리 언어로 표현한 것이다. 고급 언어에서는 한 줄로 표현된 문장이 어셈블리 언어로 바뀌면 몇줄이 된다. 이를 기계 언어로 바꾸면 ©와 같이 전혀 알 수 없는 0과 1의 조합으로 표현된다. 어셈블리 언어는 기계 언어보다 한 단계 높게 추상화된 것이고 고급 언어는 어셈블리 언어보다 한 단계 높게 추상화 된 것이다. 이처럼 제어 추상화는 단계가 올라갈수록 표현이 더욱 간결해지고 특징만 나타낸다는 장점이 있다. 프로그래밍에서 조건을 나타내는 if 문이나 반복문을 나타내는 for 문도 사용자가 사용하기 쉽게 추상화한 것이다.
모듈화#
프로그래밍은 정신적인 활동이다. 정신적인 것은 실체가 없고, 무한하고, 유연하다. 이러한 특성은 정신이 가진 장점이면서 소프트웨어의 극치다. 하지만 정신의 이러한 특성은 때로 오해나 모순 같은 문제점을 유발한다. 소프트웨어도 이러한 문제점을 그대로 상속받는다. 이러한 문제점을 극복하기 위한 노력 중의 하나가 부품화라고 할 수 있다. 객체 지향과 부품화를 동일시 할 수는 없지만 부품화라고 하는 소프트웨어의 큰 흐름은 객체 지향이 만들어지는데 지대한 공헌을 했다고 할 수 있다. 하드웨어에서 이루어지는 부품화의 예를 보자. 아래의 컴퓨터는 초창기의 컴퓨터다.

본체와 모니터와 키보드가 하나로 통합되어 있다. 이것의 문제점은 분명하다. 모니터가 고장 나면 컴퓨터를 바꿔야 한다. 키보드가 고장 나도 컴퓨터를 교체해야 한다.

그래서 위와 같이 모니터와 본체와 컴퓨터를 분리했다. 다시 말해서 부품화 시킨 것이다. 기능들을 부품화 시킨 덕분에 소비자들은 더 좋은 키보드나 저렴한 모니터를 선택할 수 있게 되었다. 또 문제가 생겼을 때 그 문제가 어디에서 발생한 것인지 파악하고 해결하기가 훨씬 쉬워진다.
위의 그림에서 모니터와 키보드 그리고 본체를 분리하는 기준은 무엇일까? 그 기준을 세우는 것이 추상화일 것이다. 위 제품의 기획자는 컴퓨터를 입력과 출력 그리고 연산 & 저장으로 분류하고 있다. 이 분류에 따라서 부품들을 모으고 분리해서 모니터, 키보드, 본체와 마우스라는 개별적인 완제품을 만들고 있다. 이 완제품들을 부품으로 조합하면 컴퓨터라는 하나의 완제품이 만들어진다.
객체 지향은 부품화의 정점이라고 할 수 있다. 하지만 우리는 아직 객체 지향을 배우지 않았다. 그래서 우리가 배운 것 중에서 부품화의 특성을 보여줄 수 있는 기능을 생각해보면 좋을 것 같다. 메소드는 부품화의 예라고 할 수 있다. 메소드를 사용하는 기본 취지는 연관되어 있는 로직들을 결합해서 메소드라는 완제품을 만드는 것이다. 그리고 이 메소드들을 부품으로 해서 하나의 완제품인 독립된 프로그램을 만드는 것이다. 메소드를 사용하면 코드의 양을 극적으로 줄일 수 있고, 메소드 별로 기능이 분류되어 있기 때문에 필요한 코드를 찾기도 쉽고 문제의 진단도 빨라진다. 그런데 프로그램이 커지면 엄청나게 많은 메소드들이 생겨나게 된다. 메소드와 변수를 관리하는 것은 점점 어려운 일이 되기 시작한다. 급기야는 메소드가 없을 때와 같은 상황에 봉착하게 된다. 메소드는 프로그래밍의 역사에서 중요한 도약이었지만, 이 도약이 성숙하면서 새로운 도약지점이 보이기 시작한 것이다.
그 도약 중의 하나가 객체 지향 프로그래밍이다. 이것의 핵심은 연관된 메소드와 그 메소드가 사용하는 변수들을 분류하고 그룹핑하는 것이다. 바로 그렇게 그룹핑 한 대상이 객체(Object)다. 비유하자면 파일과 디렉토리가 있을 때 메소드나 변수가 파일이라면 이 파일을 그룹핑하는 디렉토리가 객체라고 할 수 있다. 이를 통해서 더 큰 단위의 부품을 만들 수 있게 되었다. 객체를 만드는 법에 대해서 호기심이 생기지 않는가? 이런 호기심을 유발시키는 것이 이번 토픽의 목적이다. 객체를 만드는 법은 다음 토픽에서 알아보고 지금은 부품화에 대해서 조금 더 생각해보자.
어떤 큰 문제를 그대로 놓고 해결하는 것은 매우 어려운 일이다. 따라서 일반적으로 큰 문제를 작은 단위로 쪼개어 그것을 하나씩 핵결한다. 마찬가지로 소프트에어 개발에서 가장 먼저하는 작업이 실제로 개발할 수 있는 작은 단위로 나누는 것이다. 이렇게 작은 단위로 나누는 것을 모듈화라고 한다.
모듈의 특징#
소프트웨어 개발에서 모듈이란 규모가 큰 것을 여러 개로 나눈 조각이라고 생각할 수 있다. 또 소프트웨어 구조를 이루는 기본 단위라고도 한다. 더 구체적으로는 하나 또는 몇 개의 논리적인 기능을 수행하기 위한 명령어 집합이라고도 말할 수 있다. 독립 프로그램도 하나의 모듈이 될 수 있고 함수도 하나의 모듈이 될 수 있다. 이러한 모듈의 특징은 다음과 같다.
다른 것과 구별되는 독립적인 기능을 같는 단위(unit)이다.
유일한 이름을 갖는다.
모듈에서 또 다른 모듈을 호출할 수 있다.
다른 프로그램에서도 모듈을 호출할 수 있다.
모듈화의 원칙#
모듈화를 하기 전에 먼저 어느 정도의 크기로 나눌 것인지를 생각해야 한다. 물론 작은 단위로 나누는 것이 기본이지만 무조건 작게 나눈다고 좋은 것은 아니다. 모듈의 크기가 작아지면 그만큼 개수가 많아지고 모듈 간의 통신 횟수도 많아져 복잡해지기 때문이다. 모듈의 크기에 정답은 없으며 문제의 유형이나 특성을 고려해 결정해야 한다. 다만, 다음과 같은 원칙을 지켜야 좋은 모듈 설계라 할 수 있다.
모듈 간의 결합(coupling)은 느슨하게(loosely)한다.
모듈 내 구성 요소 간의 응집(cohesion)은 강하게(strongly)한다.
모듈화의 장점
분할과 정복의 원리가 적용되어 복잡도가 감소한다.
문제를 이해하기 쉽게 만든다.
변경하기 쉽고 변경으로 인한 영향도 적다.
유지보수가 용이하다.
프로그램을 효율적으로 관리할 수 있다.
오류로 인한 파급 효과를 최소화할 수 있다.
설계 및 코드를 재사용할 수 있다.
모듈화의 적정 수준#
모듈의 크기가 작아지면 개별적인 모듈을 하나씩 개발할 때 모듈당 개발 비용은 적게 들것이다. 그러나 모듈 간의 인터페이스도 많아져 과부하로 인해 시스템 성능이 떨이지고 복잡도가 증가한다. 그렇다면 어느 수준이 적정할까?
즉 모듈의 크기가 너무 작아 개수가 많아지면 모듈 간의 통합 비용이 많이 들고, 모듈의 크기가 너무 크면 모듈 간의 통합 비용은 상대적으로 줄어드는 대신 모듈 하나를 개발하는 데 드는 비용이 커져 모듈화의 효과를 많이 볼 수 없다. 따라서 그래프의 M 근처가 가장 적정 수준이라고 볼 수 있다.
응집도#
응집도(cohesion)는 모듈 내부에 존재하는 구성 요소 사이의 밀접한 정도, 즉 하나의 모듈 안에서 구성 요소 간에 똘똘 뭉쳐 있는 정도로 평가한다. 응집도가 높을수록 꼭 필요한 구성 요소만 모여 있고, 응집도가 낮을수록 서로 관련성이 적은 구성 요소들이 모여 있다. 응집도가 가장 높은 것은 모듈 하나가 단일 기능으로 구성된 경우이고 반대로 응집도가 가장 낮은 것은 구성 요소가 필요에 의해 모듈에 존재하는 것이 아니라 우연히 함께 묶인 경우이다.
기능적 응집(functional cohesion)은 함수적 응집이라고 한다. 응집도가 가장 높은 경우로 단일 기능의 요소가 하나의 모듈을 구성하며 단일 기능을 갖는 함수가 이에 해당된다.
순차적 응집(sequential cohesion)은 요소1의 출력을 요소2의 입력으로 사용하므로 두 요소가 하나의 모듈로 구성된 경우이다. 물론 두 요소를 개별 모듈로 만들어도 되지만, 한 모듈의 결과를 다른 모듈이 입력으로 사용하기 때문에 두 요소를 하나의 모듈로 묶어 놓았다. 두 요소가 아주 밀접하므로 하나의 모듈로 묶을 만한 충분한 이유가 된다.
교환적 응집(communication cohesion)은 정보적 응집이라고 하며 같은 입력을 사용하는 구성 요소가 하나의 모듈로 구성된다. 또 구성 요소가 동일한 출력을 만들어낼 때도 교환적 응집이 된다. 요소 간의 순서는 중요하지 않다. 교환적 응집은 순차적 응집보다 묶인 이유가 조금 약하므로 순차적 응집보다 응집력이 약하다고 할 수 있다.
절차적 응집(procedural cohesion)은 순서가 정해진 몇 개의 구성 요소가 하나의 모듈로 구성된 경우이다. 순차적 응집과 다른 점은 어떤 구성 요소의 출력이 다음 구성 요소의 입력으로 사용되지 않고 순서에 따라 수행한다. 한 요소의 출력이 다음 요소의 입력으로 사용되지 않으므로 순차적 응집보다 묶인 이유가 조금 약하다.
시간적 응집(temporal cohesion)에 의한 모듈은 모듈 내 구성 요소의 기능이 각기 다르다. 그리고 한 요소의 출력을 입력으로 상요하는 것도 아니고 요소 간에 순서가 정해지지도 않았지만 구성 요소들이 같은 시간대에 함께 실행된다는 이유로 하나의 모듈로 구성된다. 초깃값 설정 모듈이 시간적 응집의 예라고 볼 수 있다.
논리적 응집(logical cohesion)에 의한 모듈은 구성 요소 간에 공통점이 있거나 관련된 이무가 존재하거나 기능이 비슷해서 하나의 모듈로 구성된 경우이다. 예를 들어 입출력, 덧셈, 출력을 공통 요소로 보고 모듈로 묶어 놓을 수 있다.
우연적 응집(coincidental cohesion)은 구성 요소들이 말 그대로 우연히 모여 구성된다. 특별한 이유없이 몇 개의 모듈로 나누는 과정에서 우연히 같이 묶인 것으로 구성 요소 간에 관련이 별로 없어 응집도가 가장 낮다.
결합도#
결합도(coupling) 개념을 이애할 수 있는 간단한 비유를 하나 들겠다. 용돈을 받는 자녀 입장에서는 받은 용돈을 어디에 어떻게 썼는지 시시콜콜 물어보지 않는 게 좋을 것이다. 시시콜콜 간섭하면 자녀 입장에서 번거롭고 짜증난다. 모듈 간의 결합에도 짜증나는(간섭하는) 관계와 좋은 관계(간섭이 적은)가 있다. 응집도가 하나의 모듈 내에서 구성 요소 간의 연결 강도를 나타내는 기준이라면 결합도는 모듈과 모듈 사이의 관계에서 관련 정도를 나타낸다. 모듈 간에는 관련이 적을수록(loosely coupled) 상호 의존성이 줄어 모듈의 독립성이 높아지고 독립성이 높으면 모듈 간에 영향이 적어 좋은 설계가 된다. 모듈 간에 상호 연관성이 없으면 좋지만 만일 연과성이 있더라도 영향을 적게 받으러면 제어보다는 매개변수를 사용하는 데이터만의 상호 교류가 바람직하다.
객체 지향 세 가지 요소#
캡슐화#
캡슐하면 같은 캡슐로 된 약이 먼저 떠오를 것이다. 캡슐로 된 약 안에서 수많은 알갱이가 들어있지만 약을 복용할 때는 알갱이 하나하나가 어떤 기능을 하는지 알수도 없고 알 필요도 없다. 세탁기와 같은 전자 제품도 기능과 사용법만 알면 되지 내부가 어떻게 구성되어 있으며 어떤 방식으로 돌아가는지 등을 전혀 신경 쓸 필요가 없다.
캡슐화는 사용자에게 해당 객체의 기능(서비스)과 사용법만 제공해 사용하기 쉽게 하고 내부는 함부로 변겨할 수 없게 감추는 개념이다. 캡슐화하면 그림과 같이 소프트웨어 모듈인 객체 내부에 서로 관련된 데이터와 그 데이터를 조작할 수 있는 메서드를 같이 포장하는 방식으로 안에 포함된 메서드만을 사용해 데이터 값을 변경할 수 있다. 이러한 캡슐화는 블랙박스와 같은 것으로 클래스를 사용해 서로 관련된 정보와 처리 방식을 같이 묶고 외부에는 감추어두는 것이다.
캡슐화의 효과를 예를 들어 설명해보겠다. 서류가 담긴 파일 박스(모듈)에서 원하는 서류를 찾으려면 파일 박스의 구조를 잘 알고 있어야 한다. 파일 박스에 서류를 넣을 때 실수로 엉뚱한 곳에 넣으면 다음에 서류를 찾을 때 어려움을 겪는 것이다. 이 경우에 서류를 찾고 넣는 과정을 모든 책임이 사용자(프로그래머)에게 있다. 하지만 캡슐화를 사용하면 파일 박스(모듈)에서 사용자가 직접 서류를 찾고 넣는 행위가 금지되고 관리자(메서드)가 그 일을 맡아서 할 것이다. 사용자는 파일 박스의 구조를 알 필요가 없고 엉뚱한 곳에 서류를 넣는 실수도 없어진다(데이터에 직접 접근 불가능), 파일 박스의 구조가 확장되거나 변경되어도 관리자가 파악하면(메서드만 데이터 값 변경) 되므로 사용자는 필요한 서류가 무엇인지(모듈의 기능) 정도만 알면 된다. 캡슐화는 다음과 같은 장점이 있다.
추상화를 통해 문제를 쉽게 개념화할 수 있다.
객체 제공자와 객체 이용자(외부 객체)를 명확히 분리할 수 있다.
메서드의 구현 방법이 바뀌어도 사용자에게는 영향을 미치지 않아 사용하기 쉽다.
메서드의 기능만 알면 객체를 쉽게 사용할 수 있다.
객체 내 자료구조나 알고리즘이 바뀌어도 다른 객체에 미치는 영향이 적다.
캡슐화(데이터+메서드)로 객체 사이의 독립성이 구조적으로 보장된다.
객체 내부의 자료구조를 변경해도 그 객체와 인터페이스로 통신하는 사용자에게는 영향을 주지 않으므로 부담없이 자료구조를 변경할 수 있다.
프로그램을 개발할 때 다른 모듈의 구현 내용은 자세히 알 필요 없이 제공하는 기능만 알면 되므로 사용자(프로그래머)가 모듈을 이해하기 쉽다.
모듈 내의 데이터와 알고리즘을 변경하기 쉬우므로 기능을 추가하기도 쉽다.
캡슐화를 하면 외부에서는 무조건 내부 데이터를 변경할 수 없고 차단되는 것처럼 생각할 수 있다. 그러나 외부로부터 내부 데이터를 변경하지 못하도로고 할 것인지 여부는 다음에 설명하는 정보은닉에 달려 있다.
class Card:
def __init__(self, rank: str, suit: str):
self.rank = rank
self.suit = suit
def __repr__(self):
return f"{self.__class__.__name__}(rank='{self.rank}', suit='{self.suit}')"
card = Card('7', 'diamonds')
card
Card(rank='7', suit='diamonds')
from collections import namedtuple
Card = namedtuple('Card', ['rank', 'suit'])
card = Card('7', 'diamonds')
card
Card(rank='7', suit='diamonds')
from dataclasses import dataclass
@dataclass
class Card:
rank: str
suit: str
card = Card('7', 'diamonds')
card
Card(rank='7', suit='diamonds')
from typing import NamedTuple
Card = NamedTuple('Card', [('rank', str), ('suit', str)])
card = Card('7', 'diamonds')
card
Card(rank='7', suit='diamonds')
class Card(NamedTuple):
rank: str
suit: str
card = Card('7', 'diamonds')
card
Card(rank='7', suit='diamonds')
class FrenchDeck:
ranks = [str(n) for n in range(2, 11)] + list('JQKA')
suits = 'spades diamonds clubs hearts'.split()
def __init__(self):
self._cards = [
Card(rank, suit) for suit in self.suits for rank in self.ranks
]
def __len__(self):
return len(self._cards)
def __getitem__(self, position):
return self._cards[position]
deck = FrenchDeck()
print(len(deck))
print(deck[0], deck[-1])
52
Card(rank='2', suit='spades') Card(rank='A', suit='hearts')
import random
random.choice(deck)
Card(rank='2', suit='clubs')
suit_values = dict(spades=3, hearts=2, diamonds=1, clubs=0)
def spades_high(card):
rank_value = FrenchDeck.ranks.index(card.rank)
return rank_value * len(suit_values) + suit_values[card.suit]
for card in sorted(deck, key=spades_high):
print(card)
break
Card(rank='2', suit='clubs')
정보은닉#
일상에서 정보은닉의 예를 먼저 살펴보자. 가끔 친구가 무슨 생각을 하고 있는지 궁금할 때가 있다. 그러면 여러분은 어떻게 하는가? 머리속을 들여다볼 수 없으므로 많은 대화를 통해 그 친구의 생각을 알아내는 수밖에 없다. 정보은닉은 외부(다른 객체)에서 객체의 내부(데이터)를 들여다볼 수 없다는 개념이다. 다른 객체가 한 객체 내의 데이터 값을 직접 참조하거나 접근할 수 없으므로 마치 친구끼리 대화를 하듯 메서드를 통해 객체에 요청해서 값을 넘겨받아야 한다.
캡슐화는 소프트웨어 모듈인 객체 내부의 데이터와 메서드를 함께 포장하는 방식으로 캡슐의 내부와 외부를 구분한다. 그러나 캡슐화를 했다고 해서 그 자체로 내부 정보가 외부에 숨겨지지는 않는다. 이때 필요한 것이 정보은익의 원리다. 정보은익은 private설정을 통해 외부 접근을 직접 차단할 수 있어 내부를 보호하는 역할을 한다. 주로 속성(데이터)를 private로 설정해 외부로부터 데이터의 손상과 오용을 막아 안전하게 보호한다.
public 설정은 외부 접근을 허용하는 것으로주로 서비스를 제공하는 메서드를 public으로 설정한다. public로 설정한 메서드는 외부 객체와 정보를 주고받기 위한 통로이며 다른 객체에 무엇을 서비스할 수 있는지 알려준다. 이는 전자 제품에서 기능 버튼과 같은 역할이다.
public: public 퍼블릭으로 설정된 요소는 같은 시스템에 있는 모든 클래스가 접근할 수 있다. 클래스는 클래스 이름, 속성, 메서드로 구성되는데 퍼블릭으로 설정되는 부분은 주로 메서드다.private: 은닉, 프라이빗으로 설정된 요소는 같은 시스템 내의 다른 클래스가 직접 접근할 수 없고 해당 클래스의 메서드를 통해서만 접근할 수 있다. 클래스에서 대부분의 속성은 private 으로 설정된다.protected: 부분 공개(protected) 부분공개로 설정된 요소는 다른 클래스가 접근할 수 없고 해당 클래스의 메서드와 클래스를 상속받은 하위 클래스만 접근할 수 있다.
class Vector:
def __init__(self, x=0, y=0):
self.x = x
self.y = y
def __repr__(self):
return 'Vector(%r, %r)' % (self.x, self.y)
def __add__(self, other):
x = self.x + other.x
y = self.y + other.y
return Vector(x, y)
def __mul__(self, scalar):
return Vector(self.x * scalar, self.y * scalar)
a = Vector(-1, 1)
b = Vector(2, 2)
print(a + b)
print(a * 2)
a.x = 7
print(a)
Vector(1, 3)
Vector(-2, 2)
Vector(7, 1)
class Vector:
def __init__(self, x=0, y=0):
self._x = x
self._y = y
@property
def x(self):
return self._x
@property
def y(self):
return self._y
def __repr__(self):
return f'Vector({self.x}, {self.y})'
def __add__(self, other):
x = self.x + other.x
y = self.y + other.y
return Vector(x, y)
def __mul__(self, scalar):
return Vector(self.x * scalar, self.y * scalar)
a = Vector(-1, 1)
b = Vector(2, 2)
print(a + b)
print(a * 2)
a.x = 7
Vector(1, 3)
Vector(-2, 2)
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
Cell In[13], line 5
3 print(a + b)
4 print(a * 2)
----> 5 a.x = 7
AttributeError: can't set attribute
class Vector:
def __init__(self, x=0, y=0):
self._x = x
self._y = y
@property
def x(self):
return self._x
@x.setter
def x(self, value):
self._x = value
@property
def y(self):
return self._y
def __repr__(self):
return 'Vector(%r, %r)' % (self.x, self.y)
def __add__(self, other):
x = self.x + other.x
y = self.y + other.y
return Vector(x, y)
def __mul__(self, scalar):
return Vector(self.x * scalar, self.y * scalar)
a = Vector(-1, 1)
b = Vector(2, 2)
print(a + b)
print(a * 2)
a.x = 7
print(a)
Vector(1, 3)
Vector(-2, 2)
Vector(7, 1)
상속#
상속(inheritance)은 무엇인가를 물려받는다는 의미로 객체 지향에서는 상위 클래스(super class)의 모든 것을 하위 클래스(sub class)가 물려받아 내 것처럼 사용함을 의미한다. 이때 물려주는 클래스를 상위 클래스 또는 부모 클래스라고 하고 물려받은 클래스를 하위 클래스 또는 자식 클래스라고 한다. 클래스 다이어그램에서 클래스 간 상속 관계는 화살표를 사용한다. 이 때 화살표 끝은 속이 빈 삼각형 모양이다.
class A:
def ping(self):
print('ping:', self)
class B(A):
def pong(self):
print('pong:', self)
class C(A):
def pong(self):
print('PONG:', self)
class D(B, C):
def ping(self):
super().ping()
print('post-ping:', self)
def pingpong(self):
self.ping()
super().ping()
self.pong()
super().pong()
C.pong(self)
다형성#
다형성(polymorphism)은 여러 개의 형태를 갖는다 라는 그리스어에서 유래한 것으로 사전에서 찾아보면 poly(하나 이상)와 morph(형태)가 합성된 단어로 하나 이상의 형태를 뜻한다. 객체 지향에서 다형성의 개념은 오버로딩(overloading)과 오버라이딩(overriding)으로 나누어 설명할 수 있다.
오버로딩#
오버로딩은 중복 정의라고 표현하며 연산자 중복 정의와 메서드 중복 정의가 대표적이다.
from functools import singledispatch
@singledispatch
def get_sum(x: int):
return x + 2
@get_sum.register(list)
def _(x: list):
return sum(x)
print(get_sum(2))
print(get_sum([1, 2, 3, 4]))
4
10
오버라이딩#
오버라이딩은 재정의라고 표현한다. 이때 재정의란 앞에서 정의한 것을 다 무시하고 내가 새로 정의해서 사용하겠다는 것이다. 여기서는 메서드 재정의를 2가지 종류로 설명한다.
아키텍처 설계#
건물을 세울 때 가장 먼저 뼈대를 세우는 것처럼 소프트웨어를 개발할 때 뼈대를 세우는 것을 아키텍처 설계라 한다. 아키텍처는 건축학이나 건축 양식에 많이 사용되는 용어로 건물의 뼈대뿐 아니라 특성을 결정짓는 기본 구조를 일컫는다. 아키텍처는 모든 기술 분야에 적용할 수 있다. 그래서 종류도 엔터프라이즈 아키텍처, 소프트웨어 아키텍처, 시스템 아키텍처, 조직 아키텍처, 정보 아키텍처, 하드웨어 아키텍처 등 다양하다.
아키텍처의 필요성#
집안 청소를 하다보면 일이 커져 대청소가 되기도 한다. 마찬가지로 프로젝트도 시작할 때는 그렇게 복잡하지 않을 거라 생각했는데 시간이 지날수록 규모도 커지고 복잡도도 기하급수적으로 늘어나는 경우가 많다. 집안 청소는 일이 커져 대청소가 된다해도 크게 문제가 되지 않지만 프로젝트는 다르다. 대형 프로젝트를 소규모 시스템을 개발할 때 처럼 자료구조나 알고리즘 설계 정도로 끝낸다면 프로젝트가 실패할지도 모른다. 따라서 전체 시스템의 구조를 생각하며 균형과 조화를 이루도록 설계해야 한다. 그래서 등장한 것이 소프트웨어 아키텍처 개념이다.
대규모 소프트웨어를 개발하려면 복잡성의 문제를 해결해야 하는데 그 방법은 다음과 같다.
개발할 소프트웨어의 전체 구조를 가장 먼저 생각한다.
소프트웨어의 구조를 이루는 각 구성 요소를 찾는다.
각 구성 요소 간의 명확한 관계를 설정한다.
일정한 규칙을 따른다.
복잡하고 규모가 큰 소프트웨어를 개발하려면 전체적인 구조가 유기적으로 잘 구성되어야 한다. 또한 사용자가 만족할 만한 품질 좋은 소프트웨어를 개발하려면 요구분석과 설계단계부터 품질 특성을 고려해 개밸해야 한다. 따라서 잘 정의된 구조의 품질 좋은 소프트웨어를 만들려면 소프트웨어 아키텍처가 필요하다. 아키텍처 설계로 소프트웨어가 어떤 구조이고 어떻게 동작할 것인지를 예측할 수 있으며 변경에 유연하게 대처할 수 있다.
아키텍처의 특징과 기능#
소프트웨어 아키텍처는 소프트웨어의 골격이 되는 기본 구조로, 시스템 전체에 대한 큰 밑그림이다. 소프트웨어 아키텍처의 특징은 다음과 같다.
소프트웨어의 골격을 나타내는 추상화된 전체 구조를 제공한다.
소프트웨어를 이루고 있는 여러 구성 요소(서브시스템, 컴포넌트)를 다룬다.
인터페이스를 통해 소프트웨어의 구성 요소가 어떻게 상호작용하는지를 정의한다.
세부 내용보다는 중요 내용(설계자가 주관적으로 판단하고 결정)만 다룬다.
설계에 적용되는 원칙과 지침이 있다.
소프트웨어 아키텍처는 개발할 소프트웨어 구조, 주요 구성 요소, 구성 요소의 속성, 구송 요소 간의 관계와 상호작용을 판단하고 결정하는 것이다. 그러나 좀 더 넓은 의미로는 사용자의 요구사항을 충분히 반영하고 소프트웨어의 목표와 구현(코딩)을 연결하는 것으로 생각할 수 있다. 즉 아키텍처가 올바르게 설계되면 사용자의 요구사항과 완성된 프로그램의 연결을 최적화할 수 있다. 그리고 최상위 수준의 아키텍처 설계는 개발될 소프트웨어의 구조는 드러내지만 구현과 관련된 세부 내용은 감춘 채 모든 기능 요구사항과 품질 요구사항이 최대한 충족되도록 해야 한다. 소프트웨어 아키텍처를 올바르게 설계하려면 다음 기능을 고려해야 한다.
모든 이해관계자 사이의 의사소통 도구로 활용할 수 있어야 한다.
구현에 대한 제약 사항(개발 비용, 기간, 조직의 역량 등)을 정의해야 한다.
모든 이해관계자의 품질요구사항을 반영해 우선순위에 따라 시스템 품질 속성(성능, 사용성, 보안성, 안정성, 검증 가능성, 변경 용이성 등)을 결정해야 한다.
특정 문제 영역에 적합한 소프트웨어의 구성 요소를 표준화하고 패턴화해 재사용할 수 있도록 설계해야 한다.
소프트웨어 아키텍처 설계로 다음과 같은 효과를 볼 수 있다.
소프트웨어의 기본 골격이 만들어져 개발에 참여하는 사람들의 이해의 폭이 넓어지며 구현상의 문제점을 도출할 수 있다.
소프트웨어 아키텍처를 기반으로 분할 방법을 찾고 구조화를 위한 구체적인 방안을 생각할 수 있다.
설계의 원칙과 가이드를 제공할 수 있고 설계를 재사용할 수 있다.
소프트웨어 아키텍처를 기준으로 개발 조직을 만들 수 있다.
전사 조직을 소프트웨어 아키텍처에 맞게 재편할 수 있다.
품질 특성에 대한 평가 방법을 결정할 수 잇따.
아키텍처의 품질 속성#
클래스 설계 원칙#
클래스를 설계할 때 참고할 수 있는 몇 가지 원칙이 있다. 이를 객체 지향의 다섯 가지 원칙이라고 한다. 원칙을 따르지 않고 더 빨리 개발하기도 하지만 절약한 시간보다 훨씬 많은 유지보수 시간이 필요할지도 모르니 잘 알아두도록 한다. 클래스 설계를 잘하기 위한 다섯 가지 원칙을 소개한다.
단일 책임 원칙#
Gather together the things that change for the same reasons. Separate things that change for different reasons. - 로버트 C. 마틴
단일 책임 원칙(single responsibility principle, SRP)은 말 그대로 책임이 하나라는 뜻인데 여기서 책임의 의미는 변경하는 이유이고 로버트 C. 마틴이 정의했다. 즉, 클래스를 변경해야 하는 이유는 단 하나여야 한다. 따라서 단일 책임 원칙은 클래스를 설계할 때 변경하는 이유가 하나가 되도록 해야 한다는 것이다. 모든 클래스는 한 가지 책임, 즉 변경의 이유를 오직 하나만 갖도록 설계하고 클래스는 그 책임을 완전히 캡슐화 하는 것을 말한다. 그렇지 않으면 클래스 안에 두 개의 책임이 있도록 설계한다면 응집력이 떨어지는 설계가 된다. 따라서 단일 책임을 갖도록 해 응집도를 높게 하려는 것이다. 이 원칙은 객체 수가 늘어나고 구조가 복잡해지더라도 재사용 및 유지보수를 위해 지켜져야 한다. 즉, SRP 원리를 적용하면 책임 영역이 확실해지기 때문에 한 책임의 변경에서 다른 책임의 변경으로 연쇄 작용에서 자유로울 수 있다.
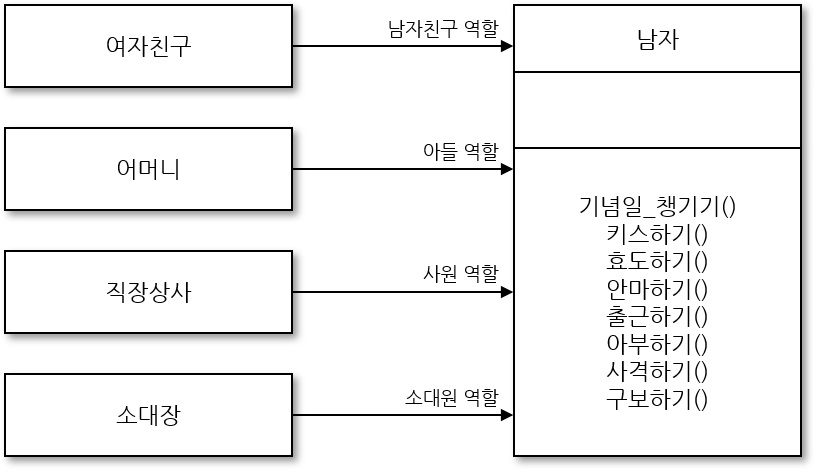
남자라는 클래스에 네 가지의 책임이 존재한다면 네 개의 클래스로 분리해 ‘변경해야 하는 이유가 오직 하나가 되도록’ 설계하는 것이 바람직하다. 예를 들어 클래스에 남자친구 역할 관련 메서드, 아들 역할 관련 메서드가 함께 있다면 두 가지 이유로 변경될 것이다. 이렇게 클래스가 변경할 이유가 두 가지라면 각 클래스로 분리해 단일 책임만 존재하도록 설계해야 할 것이다.

class StudentScoreAndCourseManager:
def __init__(self):
scores = {}
courses = {}
def get_score(self, student_name, course):
pass
def get_courses(self, student_name):
pass
class ScoreManager:
def __init__(self):
scores = {}
def get_score(self, student_name, course):
pass
class CourseManager:
def __init__(self):
courses = {}
def get_courses(self, student_name):
pass
개방-폐쇄 원칙#
자신의 확장에는 개방되어 있고 주변의 변화에 대해서는 폐쇄되어야 한다.
개방 폐쇄 원칙(open-closed principle, OCP)은 어떤 것은 개방하고 어떤 것은 폐쇄하는 것을 뜻한다. 운전자가 현재 마티즈를 타고 있지만 시간이 지나 소나타로 갈아 탈 경우 클래스를 수정해야 할 것이다. 즉, 지원 기능이 바뀌거나 늘어날 때마다 자동차 클래스는 계속 수정되어야 한다.
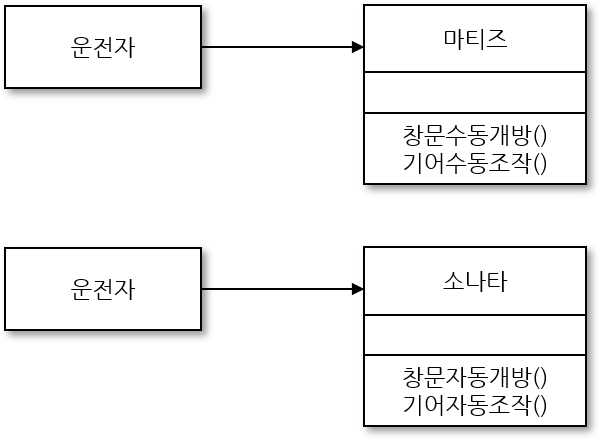
따라서 이와 같은 방식으로 수정하는 것이 맞는지 고민해보고 개방 폐쇄 원칙에 따라 설계한다면 다음과 같다. 첫째, 계속해서 바뀌는 것이 무엇인지 찾는다. 여기서는 자동차의 기능일 것이다. 자동차를 상위 클래스에 놓고 하위 클래스에 자동차의 종류를 배치해 계속 추가할 수 있도록 변경한다. 그리고 운전자가 클래스에서 이들을 호출해 사용하도록 설계 한다.
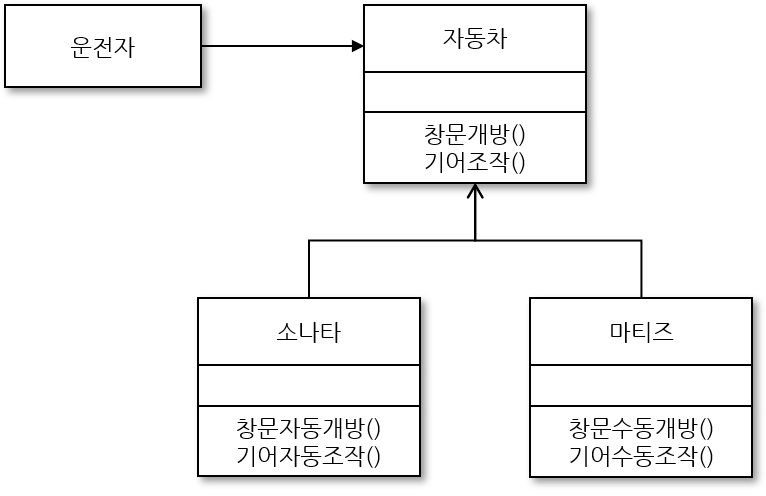
개방 폐쇄 원칙을 따라 클래스를 설계하면 다음과 같은 장점이 있다.
변경에 닫혀 있는 설계 운전자가 새로운 자동차를 운전할 때마다 자동차 클래스를 수정할 필요가 없다. 이것이 바로 변경에는 닫혀 있어야 한다. 즉 계속된 추가 사항이 있어도 그들끼리만 추가할 수 있도록 설계해야지 운전자 클래스를 수정하게 만들면 안된다는 것이다. 그래서 새로운 기능이나 종류의 추가라는 변경에는 영향을 안받도록 닫혀있어야 한다.
확장에 열려 있는 설계 새로운 기능이나 종류가 추가되어도 클래스 다이어그램의 오른쪽 상속 구조로 만들어져 있으므로 추가되는 것에 대한 클래스만 하위 클래스에 만들어주면 된다. 이것이 확장에는 열려있어야 한다’에 해당하는 말이다. 즉 새로운 클래스를 쉽게 추가할 수 있는 구조로 설계해야 한다. 결과적으로 변경이 발생할 때마다 클래스를 계속 수정하게 만들면 안된다. 이것은 개방 폐쇄 원칙에 어긋나는 클래스 설계이다.
소프트웨어의 구성요소(컴포넌트, 클래스, 모듈, 함수)는 확장에는 열려있고, 변경에는 닫혀있어야 한다는 원리이다. 이것은 변경을 위한 비용은 가능한 줄이고 확장을 위한 비용은 가능한 극대화 해야 한다는 의미로 요구사항의 변경이나 추가사항이 발생하더라도 기존 구성요소는 수정이 일어나지 말아야 하며 기존 구성요소를 쉽게 확장해서 재사용할 수 있어야 한다는 뜻이다. 재사용 코드를 만드는 기반이며 개방 폐쇄 원칙을 가능하게 하는 중요 메커니즘은 추상화와 다형성이다.

class Unit:
def __init__(self, a_type):
self.a_type = a_type
def click(unit: Unit):
if unit.a_type == 'Marine':
print('Are you gonna give me orders?')
elif unit.a_type == 'Firebat':
print('I love the smell of napalm.')
else:
raise TypeError
marine = Unit('Marine')
firebat = Unit('Firebat')
click(marine)
click(firebat)
Are you gonna give me orders?
I love the smell of napalm.
from abc import ABC, abstractmethod
class Unit(ABC):
@abstractmethod
def speak(self):
pass
class Marine(Unit):
def speak(self):
print('Are you gonna give me orders?')
class Firebat(Unit):
def speak(self):
print('I love the smell of napalm.')
def click(unit: Unit):
unit.speak()
marine = Marine()
click(marine)
Are you gonna give me orders?
리스코프 치환 원칙#
서브 타입은 언제나 자신의 기반 타입으로 교체할 수 있어야 한다.
리스코프 교체 원칙(Liskov substitution principle, LSP)은 미국 메사추세츠공과대학교(MIT)의 리스코프 교수가 제시했다. 리스코프 치환 원칙에 의하면 상위 클래스의 객체가 들어갈 자리에 하위 클래스의 객체를 넣어도 문제없이 작동해야 한다. 자식 클래스(서브 타입)는 언제나 자신의 부모 클래스(기반 타입)을 대체할 수 있다. 즉, 부모 클래스가 들어갈 자리에 자식 클래스를 넣어도 계획대로 잘 작동해야 한다는 것이다. 이를 지키지 않을 경우 부모 클래스의 의미가 변해서 is a 관계가 무너진다. 리스코프 치환 원칙에 따르면 자식 클래스의 인스턴스가 부모 클래스의 인스턴스의 행동 범위 안에서 행동해야 한다. 다시 말해, 부모 클래스의 행동 규약을 자식 클래스가 위반하면 안된다는 것이다. 그렇다면 행동 규약을 위반한 것은 어떤 경우인가? 만약 자식 클래스가 부모 클래스의 변수와 메소드를 그대로 물려 받는다면 부모 클래스의 행동 규약을 어길 수 없다. 문제가 되는 경우는 자식 클래스가 오버라이딩을 할 때이다. 오버라이딩을 잘못하는 경우는 첫째, 자식 클래스가 부모 클래스의 변수 타입을 바꾸거나 메소드의 파라미터 혹은 리턴값의 타입이나 갯수를 변경하는 것이다. 두 번째, 자식 클래스가 부모 클래스의 의도와 다르게 메소드를 오버라이딩하는 것이다.
상속에 대해 설명하면서 객체 지향에서의 상속은 조직도나 계층도가 아닌 분류도가 되어야 한다. 객체 지향의 상속은 다음 조건을 만족해야 한다.
하위 클래스 is a kind of 상위 클래스 - 하위 분류는 상위 분류의 한 종류이다.
구현 클래스 is able to 인터페이스 - 구현 분류는 인터페이스 할 수 있어야 한다.
위 두 개의 문장대로 구현된 프로그램이라면 이미 리스코프 치환 원칙을 잘 지키고 있다고 할 수 있다. 하지만 위 문장대로 구현되지 않은 코드가 존재할 수 있는데 바로 상속이 조직도나 계층도 형태로 구축된 경우이다.
출처: SOLID 법칙 中 LID
class Rectangle:
def __init__(self, width, height):
self._width = width
self._height = height
@property
def width(self):
return self._width
@property
def height(self):
return self._height
@width.setter
def width(self, width):
self._width = width
@height.setter
def height(self, height):
self._height = height
@property
def area(self):
return self._width * self._height
class Square(Rectangle):
@Rectangle.width.setter
def width(self, width):
self._width = width
self._height = width
@Rectangle.height.setter
def width(self, height):
self._width = height
self._height = height
rectangle = Rectangle(10, 30)
print(rectangle.area)
square = Square(30, 30)
square.width = 20
square.height = 10
print(issubclass(Square, Rectangle))
print(square.area == rectangle.area)
300
True
False
class Shape:
def area(self):
pass
class Rectangle(Shape):
def __init__(self, width, height):
self.width = width
self.height = height
def area(self):
return self.width * self.height
class Square(Shape):
def __init__(self, width):
self.width = width
def area(self):
return self.width ** 2
인터페이스 분리 원칙#
클라이언트는 자신이 사용하지 않는 메서드와 의존 관계를 맺으면 안된다.
로버트 C 마틴에 의한 인터페이스 분리 원칙(interface segregation principle, ISP)은 다수의 클라이언트가 일반적인 인터페이스 하나를 같이 사용하는 것보다 각 클라이언트가 필요한 대로 여러 개의 구체적인 인터페이스로 분리해 사용하는 것이 낫다는 의미이다. 그렇다고 무조건 모든 클라이언트에게 각각의 인터페이스를 제공하는 것은 아니다. 각 클라이언트가 필요로 하는 메서드군이 존재할때 인터페이스를 분리하라는 것이다. 이렇게 인터페이스를 분리해 용도가 명확한 인터페이스를 제공할 수 있어 클래스에 필요한 메서드만 선언할 수 있고 시스템의 내부 의존성을 낮춰(낮은 결합) 리팩토링을 쉽게 해 재사용성을 높일 수 있는 장점이이 있다.
사용자들이 사용하지않는 메소드들에 의존하지 않아야 한다
큰 인터페이스들을 더 작은 인터페이스들로 분리하는게 좋다
인터페이스 = 추상 클래스
출처: 파이썬 인터페이스 분리 원칙
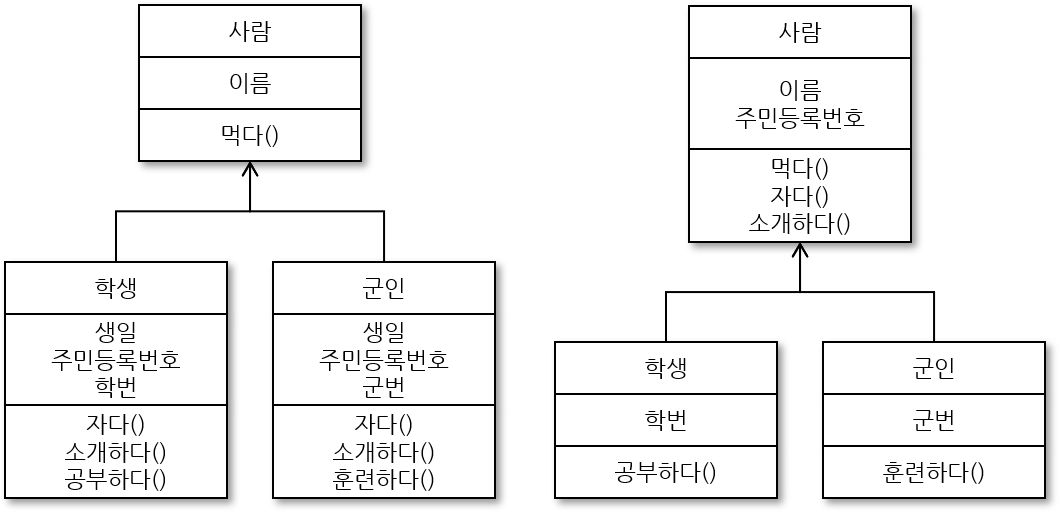
class Animal:
def eat(self):
pass
def sleep(self):
pass
def cry(self):
pass
def fly(self):
pass
class Bird(Animal):
def eat(self):
pass
def sleep(self):
pass
def cry(self):
pass
def fly(self):
pass
class Human(Animal):
def eat(self):
pass
def sleep(self):
pass
def cry(self):
pass
def fly(self):
'''???'''
class Animal:
def eat(self):
pass
def sleep(self):
pass
def cry(self):
pass
class FlyableAnimal(Animal):
def fly(self):
pass
class Bird(FlyableAnimal):
def eat(self):
pass
def sleep(self):
pass
def cry(self):
pass
def fly(self):
pass
class Human(Animal):
def eat(self):
pass
def sleep(self):
pass
def cry(self):
pass
의존성 역전 원칙#
자신보다 변하기 쉬운것에 의존하지 마라
의존성 역전 원칙(dependency inversion principle, DIP)은 구조적 디자인에서 발생하던 하위 레벨 모듈의 변경이 상위 레벨 모듈의 변경을 요구하는 위계관계를 끊는 의미의역전이다. 실제 사용관계는 바뀌지 않으며 추상을 매개로 메시지를 주고 받음으로써 관계를 최대한 느슨하게 만드는 원칙이다. 클라이언트는 구체 클래스가 아닌 추상 클래스(인터페이스)에 의존해야 한다. 객체지향 설계에서 의존 관계는 그리 반가운 단어가 아니다. 서로의 관계가 의존적이라는 것은 결합도가 높다는 것이고 이는 클래스 설계에서 좋은 관계가 아니다.
지나치게 많은 추상 메서드를 가진 거대한 인터페이스 하나를 관련된 추상 메서드들만 모여있도록 작은 크기의 인터페이스로 분리하는 것이다. 지나치게 큰 인터페이스는 상속받을 자식 클래스가 필요하지 않은 메서드를 강제로 오버라이딩하게 만들기 때문이다. 인터페이스가 서로 관련성이 높은, 적절한 개수의 추상 메서드를 포함하게 될 때 역할 인터페이스라고 불리는데 거대한 인터페이스 하나보다는 작은 역할 인터페이스 여러 개 있는 것이 각 클래스가 본인의 역할에 맞는 인터페이스를 상속 받을 수 있게 하여 더 효율적이다. 이는 각 클래스의 기능을 쉽게 파악할 수 있는 장점이 있다. 인터페이스를 분리하는 기준은 상황에 따라 다르기 때문에 관련 있는 기능끼리 하나의 인터페이스에 모의되 지나치게 커지지 않도록 크기를 제한한다는 생각을 가지고 설계해야 한다.
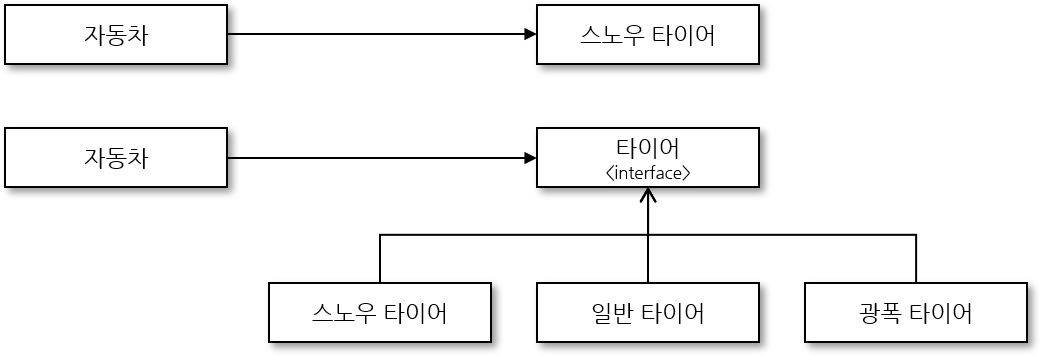
class Cat:
def speak(self):
print('meow')
class Dog:
def speak(self):
print('bark')
class Sheep:
def speak(self):
pass
class Cow:
def speak(self):
pass
class Zoo:
def __init__(self):
self.cat = Cat()
self.dog = Dog()
self.Sheep = Sheep()
self.Cow = Cow()
class Animal:
def speeak(self):
pass
class Cat(Animal):
def speak(self):
print("meow")
class Dog(Animal):
def speak(self):
print("bark")
class Zoo:
def __init__(self):
self.animals = []
def addAnimal(self, animal:Animal):
self.animals.append(animal)
def speakAll(self):
for animal in self.animals:
animal.speak()
zoo = Zoo()
zoo.addAnimal(Cat())
zoo.addAnimal(Dog())
zoo.speakAll()
meow
bark