Network in Network#
2014년에 ICLR에 발표된 Network In Network 논문이다. 저자들은 수용영역안에서 local patches에 대한 모형의 차별성을 높이기 위해 Network In Network의 구조를 제시했다. 전통적인 CNN 모형은 비선형 활성화 함수와 함께 사용되는 선형 필터를 사용한다. 반면, Network In Network는 이전 CNN 모형보다 수용영역 안에 데이터를 더 복잡하게 추상화할 수 있는 마이크로 신경망(micro neural network)를 사용한다.
전통적 Convolutional Neural Networks는 선형적으로 분리가능한 상황에서 효과적이지만, 좋은 추상화는 대부분 input에 대해 비선형적이다. 이 때 Convolutional Neural Networks는 비선형 잠재공간을 학습하기 위해서 무리하게 되는데 이는 학습에 좋지 않은 영향을 미친다. 따라서 저자는 저차원의 결합으로 더 나은 고차원의 feature를 만드는 것보다 고차원으로 결합하기전에 각 local patch(저차원)에서 더 나은 추상화를 하는 것이 유리하다고 주장한다.
일반적으로 사용되는 CNN 필터는 데이터 패치(data patch)에 대한 일반화 선형 모형(generalized linear model, GLM)이다. 연구팀은 GLM의 추상화 수준이 낮지만 GLM에 비선형 함수 추정기(approximator)로 대체한다면 모형의 추상화 성능을 향상할 수 있다고 주장했다. GLM은 선형적으로 분리될 수 있는 잠재공간 하에서만 좋은 성능을 보장할 수 있다. 일반적으로 잠재공간은 비선형적인데도 불구하고 이는 GLM을 사용하는 기존 CNN이 암시적으로 잠재공간이 선형적으로 분리가능하다는 가정을 하게 만든다.
따라서, Network In Network에서는 GLM을 비선형 함수 추정기인 마이크로 신경망으로 대체한다. 마이크로 신경망은 모형의 성능을 향상시키기 위해 전역 평균 풀링계층(global average pooling)을 제안했다. 전역 평균 풀링계층을 사용하면 모형에 대한 해석이 쉬워지고 분류에 필요한 FC(fully-connected layer)를 사용하면 발생하는 과적합에도 영향을 덜 받을 수 있다.
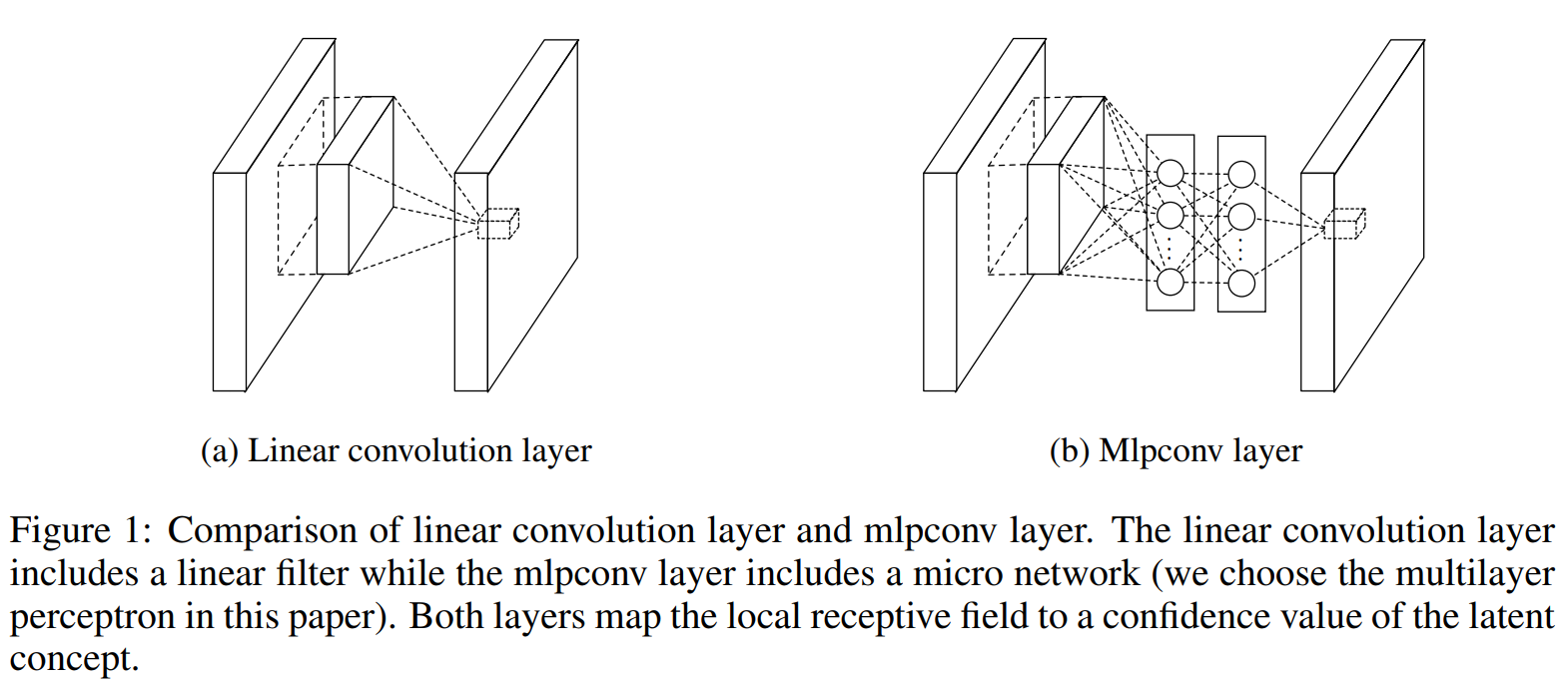
(a)는 선형 합성곱 신경망이고, (b)는 비선형 활성화 함수와 함께 여러개의 fully connected layer로 이루어진 Multilayer Perceptron이 입력 local patch를 output feature vector와 매치시키는 모습을 보여준다. Multilayer Perceptron이 여러개의 fully connected layer이루어져 있기 때문에 모든 local receptive field는 공유한다.
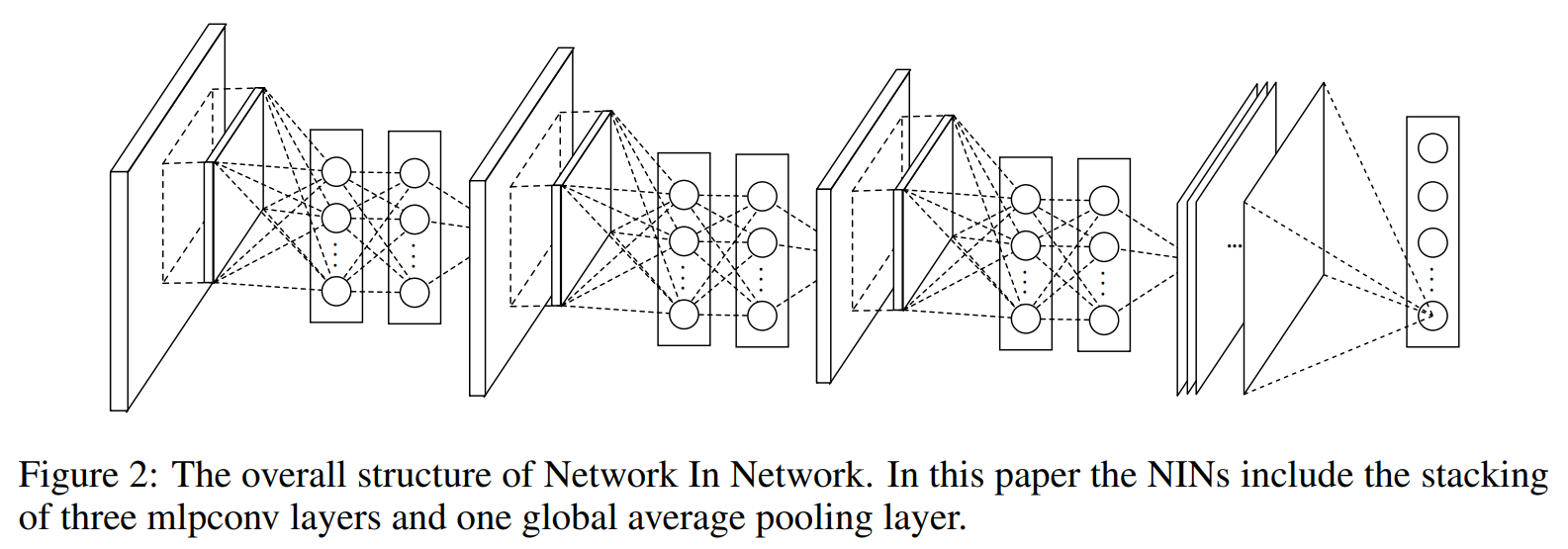
NIN에서는 classification을 위해 fully connected layer 대신 global average pooling을 사용한다. global average pooling은 마지막 mlpconv layer에서 나온 feature map의 공간 별 평균을 통해 class에 대한 confidence를 출력할 수 있게한다. global average pooling을 사용하면 좀 더 의미있는 해석이 가능하고, dropout에 의존적이고 over-fitting의 가능성이 높은 fully connected layer에 비해서, global average pooling자체가 구조적으로 regularizer의 역할을 하기 때문에 전반적으로 overfitting을 방지하는 효과를 얻을 수 있다(fully connected layer는 파라미터 수가 폭발적으로 증가하는 한편, global average pooling은 파라미터 수가 늘어나지 않기 때문에 over-fitting 되지 않는다.).
feature map에 fully-connected layer를 사용하게 되면 모든 feature map의 정보가 연결되기 때문에 각 class가 어떤 이유로 선택되었는지 알기가 어렵다. 하지만 global average pooling는 conv층을 통과한 각각의 feature map을 평균한 것 이기 때문에 어느정도 각 feature map의 특성을 가지고 있다고 할 수 있다. 이는 모델의 해석에 도움을 줄 수 있다. 또한 fully-connected layer의 Weight와 달리 훈련데이터에 최적화 해야 할 parameter가 없기 때문에 이 layer에서 만큼은 overfitting을 방지할 수 있다는 장점도 있다.
GoogleLeNet에서 인용된 논문이고 Inception module의 컨셉을 설계하는데 참고한 논문이다. gap와 1x1 convolution layer을 제시한 좋은 논문이라고 생각한다. 특히, 1x1 convolution layer의 channel reduction 효과는 한정된 컴퓨팅 자원하에서 유용한 tool이 될 것 같다.
from torch import nn
class NIN(nn.Module):
def __init__(self, num_classes):
super(NIN, self).__init__()
self.num_classes = num_classes
self.features = nn.Sequential(
nn.Conv2d(3, 192, 5, padding=2),
nn.ReLU(inplace=True),
nn.Conv2d(192, 160, 1),
nn.ReLU(inplace=True),
nn.Conv2d(160, 96, 1),
nn.ReLU(inplace=True),
nn.MaxPool2d(3, stride=2, ceil_mode=True),
nn.Dropout(inplace=True),
nn.Conv2d(96, 192, 5, padding=2),
nn.ReLU(inplace=True),
nn.Conv2d(192, 192, 1),
nn.ReLU(inplace=True),
nn.Conv2d(192, 192, 1),
nn.ReLU(inplace=True),
nn.AvgPool2d(3, stride=2, ceil_mode=True),
nn.Dropout(inplace=True),
nn.Conv2d(192, 192, 3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(192, 192, 1),
nn.ReLU(inplace=True),
nn.Conv2d(192, self.num_classes, 1),
nn.ReLU(inplace=True),
nn.AvgPool2d(8, stride=1)
)
self._initialize_weights()
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), self.num_classes)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
m.weight.data.normal_(0, 0.05)
if m.bias is not None:
m.bias.data.zero_()
---------------------------------------------------------------------------
ModuleNotFoundError Traceback (most recent call last)
Cell In[1], line 1
----> 1 from torch import nn
3 class NIN(nn.Module):
4 def __init__(self, num_classes):
ModuleNotFoundError: No module named 'torch'