VGGNet#
VGGNet은 2014년 옥스포드 대학의 연구팀 VGG에 의해 개발된 모형으로 ImageNet 대회에서 준우승을 한 모형이다. VGGNet은 Karen Simonyan과 Andrew Zisserman에 의해 2015 ICLR에 발표된 Very deep convolutional networks for large-scale image recognition 논문이다. VGGNet은 AlexNet과 유사하지만 병렬적 구조로 이뤄지진 않았다. 현재를 기준으로 이미지 분류기의 역사를 살펴보았을 때 VGGNet부터 시작해서 네트워크의 깊이가 매우 깊어졌다.

2012년에서 2013년 사이 대회 우승 모형들은 8개의 계층으로 구성되었다. 반면 2014년의 VGG19는 19층으로 구성되었고, GoogLeNet은 22층으로 설계되었다. 저자들의 네트워크의 깊이를 깊게 만드는 것이 성능에 어떤 영향을 미치는지를 확인하고자 했다. 그리고 앞으로 배울 ResNet의 경우 152개의 계층으로 구성된다. 네크워크가 깊어지면 깊어질 수록 성능이 매우 좋아진다. VGGNet은 이해하기 쉬운 구조와 좋은 성능으로 그 대회에서 우승을 거둔 매우 복잡한 GoogLeNet보다 더 많은 인기를 얻었다.
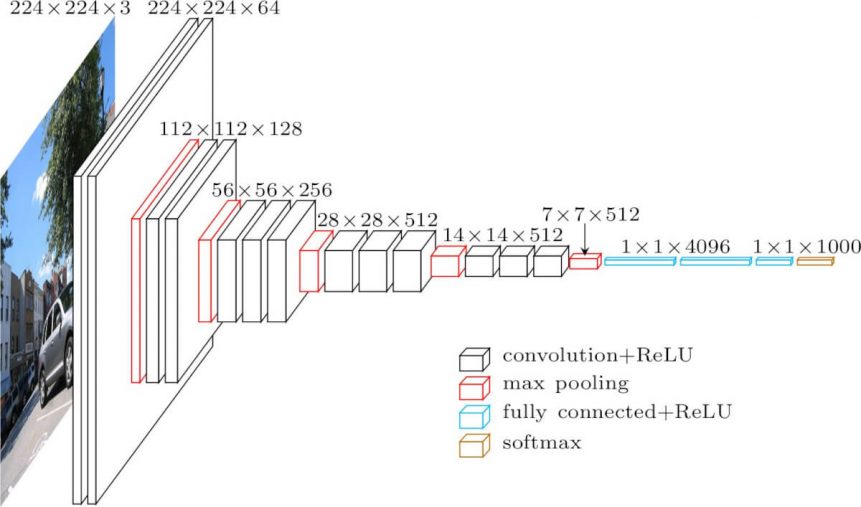
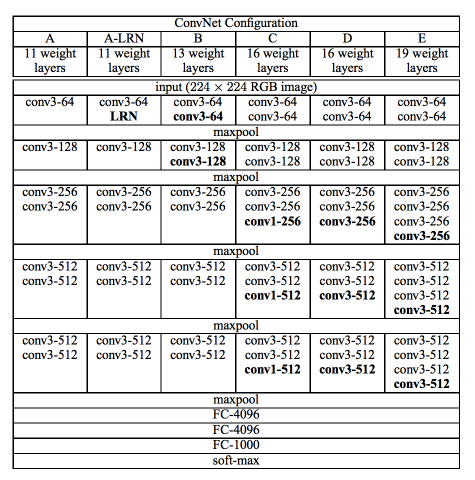
VGG 연구팀은 깊이의 영향만을 최대한 확인하고자 CNN의 커널 사이즈를 가장 작은 \(3 \times 3\)으로 고정했다. VGG 연구팀은 6개의 구조(A, A-LRN, B, C, D, E)를 만들어 네트워크의 깊이에 따른 성능 변화를 비교하였다. 저자들은 AlexNet과 VGG-F, VGG-M, VGG-S에서 사용되던 LRN(local response normalization)이 A 구조와 A-LRN 구조의 성능을 비교함으로 성능 향상에 별로 효과가 없다고 실험을 통해 확인했다. 따라서 더 깊은 B, C, D, E 구조에는 LRN을 적용하지 않았다. 또한, 저자들은 레이어의 깊이가 11층, 13층, 16층, 19층으로 깊어지면서 분류기의 오류가 감소하는 것을 관찰했다. 즉, 깊어질수록 성능이 좋아진다는 것이었다.
VGGNet은 CNN 필터의 크기를 \(3 \times 3\)으로 고정한 이유는 특징맵이 필터를 거칠 수록 특징맵의 크기는 줄어들기 때문이다. 그래서 필터의 사이즈가 클 수록 이미지가 줄어드는 것이 빨라지고 레이어를 깊게 만들 수 없을 것이다. 따라서 필터를 가장 작은 사이즈인 \(3 \times 3\)으로 설정하여 레이어를 거치더라도 큰 필터보다 적게 줄어 상대적으로 레이어가 깊은 모델을 만들 수 있어 사용했을 것이라 생각한다. 또한, 파라미터의 개수가 줄어드는 효과와 ReLU가 활성화 함수로 들어갈 수 있는 곳이 많아진다는 장점이 있어 사용했다고 한다.
아래의 그림과 같이 \(3 \times 3\) 필터로 두 차례 컨볼루션을 하는 것과 \(5 \times 5\) 필터로 한 번 컨볼루션을 하는 것이 결과적으로 동일한 사이즈의 특성맵을 산출한다. \(3 \times 3\) 필터로 세 차례 컨볼루션 하는 것은 \(7 \times 7\) 필터로 한 번 컨볼루션 하는 것과 대응된다.
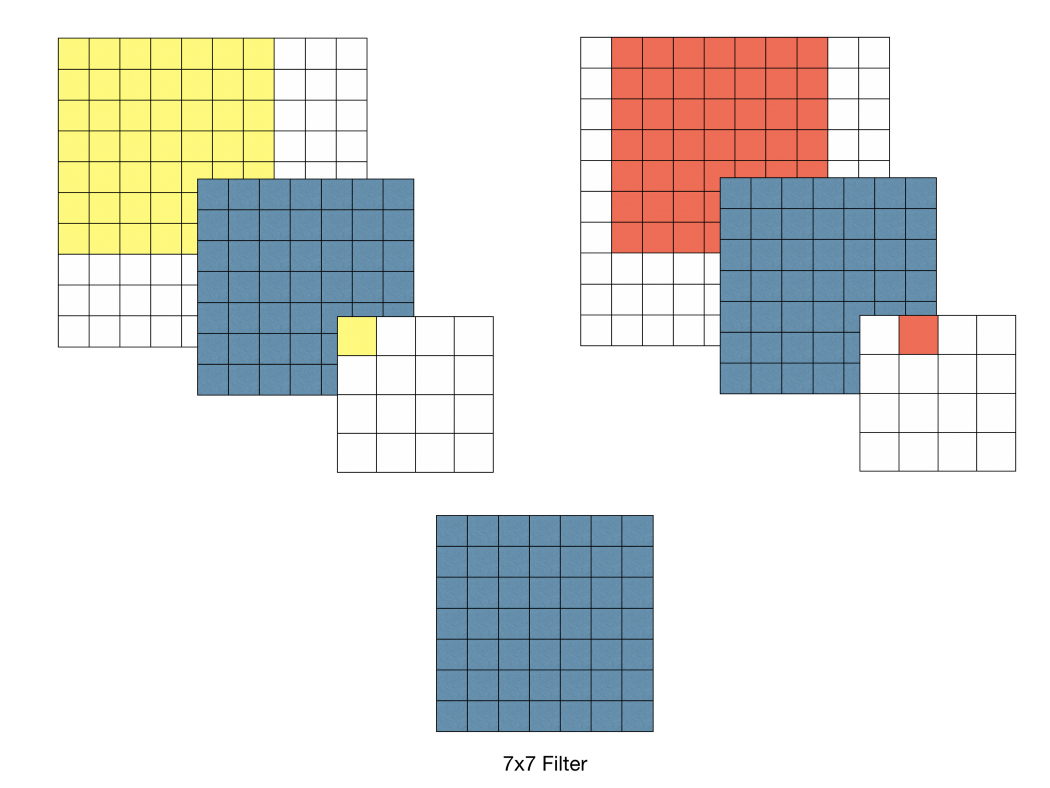
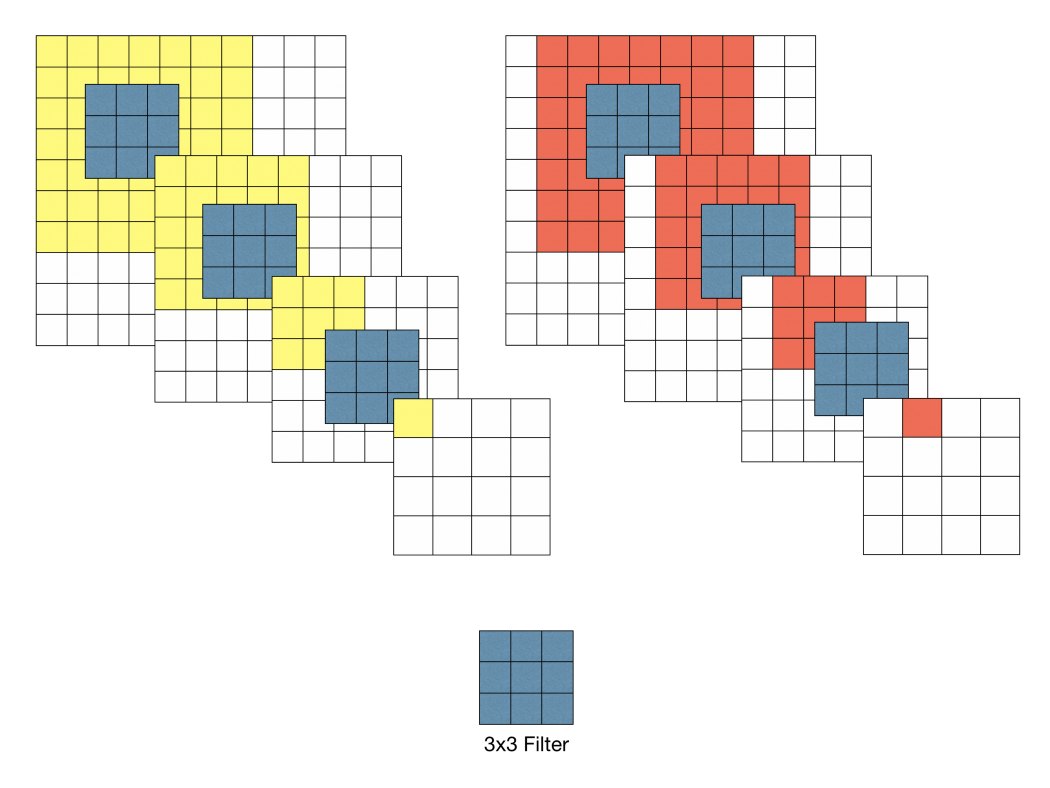
먼저 필터의 사이즈를 작게 하므로서 얻는 장점으로는 \(7 \times 7\)의 레이어에 \(5 \times 5\)의 필터를 적용하면 49개의 파라미터를 가지며 \(3 \times 3\)의 특징맵이 만들어진다. 하지만 \(3 \times 3\)의 필터를 3번 적용시키면 \(5 \times 5\)의 필터와 동일한 효과를 볼 수 있을 뿐더러 파라미터의 개수도 더 적은 27개이다. 같은 효과를 가지지만 더 적은 파라미터를 나온다면 학습의 효율성이 좋아질 것이다. 그렇기 때문에 CNN 필터의 사이즈를 \(3 \times 3\)으로 설정한 것이다(파라미터의 개수가 줄어들 수록 정규화를 할때 이점을 얻을 수 있다고 한다). 그래서 VGG16의 모든 필터는 \(3 \times 3\), stride = 1으로 설정되어 있다. ReLU 함수를 적용시켜 비선형성을 가지게 하여 CNN에서 레이어를 쌓는다는 의미를 가지게 하는데 이 함수가 많아지면 비선형성이 적용되어 레이어의 깊이가 깊어질 수록 학습의 효과를 증폭시키게 되는 것이다.
from typing import Union, List, Dict, Any, cast
import torch
import torch.nn as nn
class VGG(nn.Module):
def __init__(
self, features: nn.Module, num_classes: int = 1000, init_weights: bool = True, dropout: float = 0.5
) -> None:
super().__init__()
self.features = features
self.avgpool = nn.AdaptiveAvgPool2d((7, 7))
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(True),
nn.Dropout(p=dropout),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(p=dropout),
nn.Linear(4096, num_classes),
)
if init_weights:
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode="fan_out", nonlinearity="relu")
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
def make_layers(cfg: List[Union[str, int]], batch_norm: bool = False) -> nn.Sequential:
layers: List[nn.Module] = []
in_channels = 3
for v in cfg:
if v == "M":
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
v = cast(int, v)
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
if batch_norm:
layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)]
else:
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v
return nn.Sequential(*layers)
cfgs: Dict[str, List[Union[str, int]]] = {
"A": [64, "M", 128, "M", 256, 256, "M", 512, 512, "M", 512, 512, "M"],
"B": [64, 64, "M", 128, 128, "M", 256, 256, "M", 512, 512, "M", 512, 512, "M"],
"D": [64, 64, "M", 128, 128, "M", 256, 256, 256, "M", 512, 512, 512, "M", 512, 512, 512, "M"],
"E": [64, 64, "M", 128, 128, "M", 256, 256, 256, 256, "M", 512, 512, 512, 512, "M", 512, 512, 512, 512, "M"],
}
def _vgg(arch: str, cfg: str, batch_norm: bool, pretrained: bool, progress: bool, **kwargs: Any) -> VGG:
if pretrained:
kwargs["init_weights"] = False
model = VGG(make_layers(cfgs[cfg], batch_norm=batch_norm), **kwargs)
if pretrained:
state_dict = load_state_dict_from_url(model_urls[arch], progress=progress)
model.load_state_dict(state_dict)
return model
def vgg11(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> VGG:
r"""VGG 11-layer model (configuration "A") from
`"Very Deep Convolutional Networks For Large-Scale Image Recognition" <https://arxiv.org/pdf/1409.1556.pdf>`_.
The required minimum input size of the model is 32x32.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _vgg("vgg11", "A", False, pretrained, progress, **kwargs)
def vgg13(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> VGG:
r"""VGG 13-layer model (configuration "B")
`"Very Deep Convolutional Networks For Large-Scale Image Recognition" <https://arxiv.org/pdf/1409.1556.pdf>`_.
The required minimum input size of the model is 32x32.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _vgg("vgg13", "B", False, pretrained, progress, **kwargs)
def vgg16(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> VGG:
r"""VGG 16-layer model (configuration "D")
`"Very Deep Convolutional Networks For Large-Scale Image Recognition" <https://arxiv.org/pdf/1409.1556.pdf>`_.
The required minimum input size of the model is 32x32.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _vgg("vgg16", "D", False, pretrained, progress, **kwargs)
def vgg19(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> VGG:
r"""VGG 19-layer model (configuration "E")
`"Very Deep Convolutional Networks For Large-Scale Image Recognition" <https://arxiv.org/pdf/1409.1556.pdf>`_.
The required minimum input size of the model is 32x32.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _vgg("vgg19", "E", False, pretrained, progress, **kwargs)
---------------------------------------------------------------------------
ModuleNotFoundError Traceback (most recent call last)
Cell In[1], line 3
1 from typing import Union, List, Dict, Any, cast
----> 3 import torch
4 import torch.nn as nn
7 class VGG(nn.Module):
ModuleNotFoundError: No module named 'torch'